作为一个前端开发者,是后台数据的第一个消费者,并且日常与 AJAX 等前后端数据交互,如果对与 WEB 核心的 HTTP
协议不熟悉实在是不应该,并且不了解 HTTP 协议的话,长时间下来有可能会成为你的短板。
##URL 与 URI
提及 HTTP 协议,第一个部分肯定要知道 URL 是什么。
URI 解析格式:1
<scheme>://<username>:<password>@ host:port/path/;<params>?<query>#frag
各字段:
scheme:协议名,采用的是什么协议,例如 http,https,file 等。
username,password: 网页的用户名与密码,现在的网页很少这样出现在 url 中。
host, port: 主机域名与端口号。
params: 参数,用于请求的传参,前面使用 ; 来分割区分。
query: 查询字符串,前面使用 ? 来分割区分,多用于 GET 请求的传参。
frag: 前面用 # 来分割,表示文档片段,以前常见于 a 标签的点击后显示,现多用于单页面应用提高页面速度,
使用 hashchange 事件监听。
URI 表示的是更为广泛的唯一资源标识符,而 URL 表示的是特殊的 URI,表示唯一资源定位符。
##HTTP 报文
HTTP 有两种报文,一种是客户端发送请求时的请求报文,一种是服务端响应客户端请求时的响应报文。我们来看一些
真实的 HTTP 报文段这样可以方便真正理解。
###请求报文
先来看通用头部: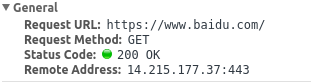
Request URL: 请求的 url,这里可以看到请求的 url 是 https://www.baidu.com/,即通俗的 ajax 请求中的 url。
Request Method: GET, 这里请求方法是使用 GET 方法,除了 GET ,还有 POST ,DELETE,PUT 等请求。
Status Code: 200 OK, 这里是状态码,前面的 200 是 HTTP 状态码,后面的 OK 是状态码的文本信息。
Remote Address:从字面上看就很好理解,这是远程服务器的 IP 地址与端口号,这里 IP 地址是 14.215.177.37,
端口号是 443。
一个百度首页的请求首部: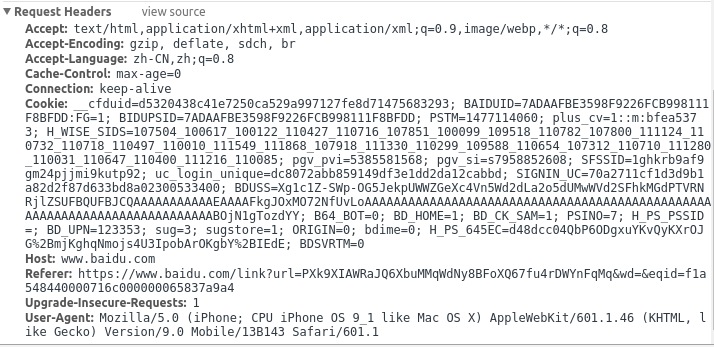
Accept:接收文档/信息的格式,这里可以看到文档格式有 text/html, application/xhtml+xml, application/xml,
image/webp,前面三个表示的是文本文件,后面一个是表示图像文件的格式,其中看到报文中有 q=0.9/0.8 这样的字样
表明的是文档格式的优先级,默认优先级为 1, 优先级设置是 0 - 1,形如 0.9,0.8 等,使用 ;来隔开,这里的意思是
文本文档的优先级为 0.9,优于图像文件的优先级 0.8。
Accept-Encoding: 文档的压缩模式,使用 gzip 压缩的文档优先。
Accept-Language: 文档语言类型,这里是 zh-CN 表示采用中文编码。
Cache-Control: 缓存控制字段,max-age 表示缓存有效时间,max-age=0 表示缓存服务器不对资源有效性验证,直
接将请求转给源服务器。
Connection: 有两个值,一个是 close,一个是 keep-alive。区别请阅读下面的 HTTP 持久链接章节。
Cookie: 这里存储的值就是我们常说的 cookie 了,也就是需要在客户端较长时间存储的信息。
Host: 主机域名。
Referer: 说明发起这个请求的原始资源 URL。
User-Agent: 用户代理,一般是用于判别浏览器的类别。从这里可以知道访问的是哪种浏览器。
另外增加几个这里没有体现但我觉得同样重要的首部字段:
If-Modified-since: 可能有一些敏感的同学会注意到有时候我们访问某个 html 文件或者图像文件的时候,看控制
台的信息的时候会看到 304 状态码,而 304 与这里的 If-Modified-since 有关,浏览器会缓存一些静态文件,当再次
访问这些文件的时候,浏览器会发出一个条件 GET 请求,如果文件的修改日期与原先的相同,那么就认为文件没有修改
就会继续使用本地的缓存文件,极大节约了带宽,此时返回的状态码就是 304 Not Modified。
###响应报文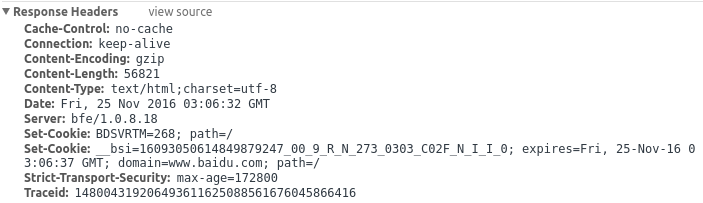
Cache-Control: 缓存控制字段,这里使用 no-cache ,表示不缓存文件,强制客户端向服务器确认文件有效性。
Connection: 说明持久链接的,请阅读下面的 HTTP 链接章节。
Content-Encoding: 文档的压缩模式。使用 gzip 模式。
Content-Length: 文档文件长度。这里有 56821 字节。
Content-Type: 文档类型,这里是 text/html 的 html 文档,使用 utf-8 编码。
Date:
Server: 表明使用的服务器的版本,类型等,与客户端的 User-Agent 字段类似。
Set-Cookie: 通知客户端创建一个 cookie 文件,设置保存路径为 /,存储的值。
另外有一个我觉得挺有用的字段:
ETag:服务器会为每一个服务器上的文件创建一个 Etag 记录,来区分文件的不同,一个简单的例子就是一些网站
域名相同,但是中文的系统访问的是中文网页,英文系统访问的是英文网页。
##HTTP 状态码
###类别
- 1xx 信息状态码
- 2xx 成功状态码
- 3xx 重定向状态码
- 4xx 一般是客户端错误
- 5xx 一般是服务端错误
###例子
404:页面或请求无法找到。
500:服务器出错。
502:服务器错误,一般是后台代码语法有错。
##HTTP 缓存
HTTP 缓存作为 HTTP 协议的一大部件,是相当重要的。
###缓存服务器
一般来说,网络服务运营商都会有自己的缓存服务器,缓存服务器最大的作用就是缩短访问文件的时间,减轻源服务器
的压力。
缓存服务器会将客户端访问过的文件缓存起来,设置一个过期时间,或者客户端使用 cache-control 字段来控制缓存。
###如何保证客户端访问的文件是有效且最新版本
在访问的静态文件后面加上版本号,例如 ?version=123 这样的字样,在前端这边我一般会使用 gulp-rev 这个插件去
动态地替换静态文件的引用,这样保证线上版本是引用了你想要的最新的版本。
##HTTP 持久链接
HTTP 中的 connection 中有两个值,一个是 close, 一个是 kepp-alive。在 HTTP 1.0 以前的版本,HTTP 的链接是
默认 close 值的,而在 HTTP 1.1 之后,则默认 connection:keep-alive。
###持久连接与非持久连接的对比
一个 HTML 文档中,不仅仅包含了 HTML 结构,很多时候在今时今日,一个 HTML 文件会包含很多像 CSS 样式文件,
image 图像文件,script 的 js 文件的引用,但是如果假设这些静态文件都放置在服务器上,在 HTTP 1.0 以前的
版本中,浏览器与服务器之间会先建立一个 HTTP 链接传输完 HTML 文件后关闭连接,然后另外为所引用的文件建立
连接来传输。如果是这样,会消耗很多时间与带宽在建立 TCP 连接上,TCP 需要三次握手,而每一个静态文件都需要
这样一个连接来传输,无疑是灾难。
而在 HTTP 1.1 后的 HTTP 版本,采用了 keep-alive 持久连接,一旦建立起一个 HTTP 连接之后,如果该 HTML 所引
用的位于服务器上的静态文件会继续使用这个连接而无需重新建立连接。
##Session 与 Cookie
从字面上来说,session 是一次会话,cookie 则会较长时间地保存某些信息。其实实际上,session 也是建立在 cookie 上的。
因为 HTTP 的无状态,这个在一方面提供给 HTTP 快速便捷地传输,但是在另一方面面对今日的复杂的业务需求,它可
能力不从心。因此为了提供记录状态,出现了 sesison 与 cookie 技术。
###Cookie
cookie 是非常常用的,它的用途非常广泛,可以跨页面通信,可以记录用户访问记录以达到推荐某些符合用户需求的
内容。可惜的是,在客户端没有相对应便捷的函数能够便捷调用 cookie ,必需自己封装一个函数来调用 cookie。
但今天我不想在这里谈及 cookie 函数的实现,详细情况请阅读本人的 Vue 项目总结。今天我想说明 cookie 的各个属性。
各属性如下:
domain: 域名,某域名下的 cookie,一般不设置,因为 XSS 攻击容易获取某个域名下的 cookie。
path: cookie 文件存放路径。
secure: 安全属性,设置为 HTTPOnly 可以防止 XSS 攻击。
expires: 过期时间。
服务端可以通过 set-cookie 来通知客户端来创建一个 cookie,一旦有请求就将 cookie 里面的存值传给服务端。这
也就是为什么不建议 cookie 存储过多信息,因为会增加请求压力。
###Session
session 与 cookie 不同,session 的值是存在服务端的,所以不像 cookie 那样安全性较低,但是相对应的会增加服
务器的压力,一般来说 session 在各大后端框架都有封装,像 express 3.x 可以使用 express.session 来设置 session。一般会使用 session 来做二次免登录,免于泄露密码与用户信息。
##常见的 WEB 攻击
因为 HTTP 自身的来者不拒,传输不加密的特点,虽然是 HTTP 能够快速方便地传输,但是也使得 HTTP 协议不安全。
常见的 WEB 攻击有 XSS 攻击,SQL 注入攻击,会话劫持等。
###XSS 攻击
XSS 攻击,相信大家会有所耳闻,但是它的中文名其实叫做跨站脚本攻击。它有三种类型,储存型、反射型、DOM 型。
储存型是将脚本留在服务器中,不断地从内部发出攻击。
反射型是诱导用户点击某些链接而后发送了自己的信息给攻击者,攻击者利用这样的信息攻击服务器。
DOM 型是本地行为,在更新 DOM 节点的时候发生。
防御 XSS 攻击一般有在两端(客户端,服务端)都加上数据验证,验证数据是否正确且从真正的源发出,另外还有对
数据进行转码,或在 HTTP 头部加上 X-XSS-Protection=1 这样的头部。
编码其实一方面为了能够保证传输参数的正确性,另一方面是为了防止黑客的直接注入。编码降低了潜在的语义攻击。1
当构建参数传入{“name” : ”Mitty&isLogin=true”}。此时拼接字符串编成了http://www.baidu.com?name=Mitty&isLogin=true,如果isLogin真的是有意义的queryKey时,直接造成服务器接收了额外的参数。
###SQL 注入
SQL 注入生效需要两个先决事件,1.需要使用 SQL 操作数据库,2.用户传入的数据直接被写入数据库中。
为了预防这个,可以对 url 编码并对用户的输入进行验证。
###DDOS 攻击
全名叫做分布式拒绝服务攻击,举个很简单的例子就是像麦当劳里面闲坐的人太多会导致真正想吃东西的客户没有座位
坐下来。
常见的 DDOS 攻击手段有 TCP SYN 泛洪,TCP ACK 泛洪,DNS 查询泛洪等。
###CSRF
中文名叫跨站请求伪造,利用 A 网站访问后的信任关系,登录 B 网站,B 网站可以利用这个信任关系,来访问网站。
这也就是为什么不建议开启跨域请求首部的原因,限定调用请求的网站有助于安全建立。
预防 CSRF 可以检查 token,token 是请求时候生成的一个 token,每个用户有一个特殊的 token,也就是令牌验证。
或检查请求头部 source origin == target origin ? 是否同源。
##附录:
###max-age=0 与 no-cache 有什么不同?
有区别,设置 max-age 浏览器还是会缓存文件的,但是 no-chache 就不会缓存文件,max-age=0 设置之后再次访问
浏览器只会发起一个条件 GET 请求,强制向源服务器询问是否过期,如果不过期则会使用本地缓存,但是 no-chache
每次都会请求一个全新的文件。
###max-age 与 expires 哪个更有效?
Expires 在 HTTP 1.0 之前就已经制定了,而 cache-control 的 max-age 是在 HTTP 1.1 之后才制定的,所以想要更
有效地制定有效时间光用 max-age 是不行的。Expires 的时间如果客户端与服务端不一致的话,会导致 Expires 配置
出错。max-age 是指文档被访问之后的存活时间,而 Expires 指的是文件的最后访问时间,max-age 指的是文档请求时
间。
###如何在 HTML 页面使用 HTTP 头部的设置?
方法:使用 meta 标签1
2
3<meta http-equiv="Cache-Control" content="no-cache" />
<meta http-equiv="expires" content="...date" />
<meta http-equiv="cache-control" content="public" />